Publier des données en opendata en continu
Cendrine HOARAU - Parc national des Ecrins / Juin 2021
Le droit d'accès des citoyens à l'information publique émerge en 1978 avec la loi dite CADA, et les mesures prises pour ouvrir les données publiques en France s’accélèrent depuis 2015 avec la loi dite « Valter » qui établit le principe de gratuité pour la réutilisation des données publiques. Puis l’année suivante, en 2016, la loi pour une République Numérique dite « Lemaire » instaure l’obligation pour les établissements publics de publier en ligne dans un standard ouvert leurs principaux documents, y compris leurs codes sources, ainsi que leurs bases de données et les données qui présentent un intérêt économique, social, sanitaire ou environnemental. Récemment, le 27 avril 2021, une nouvelle circulaire du Premier Ministre a vu le jour pour donner suite au rapport « Bothorel », positionnant la politique d’ouverture des données publiques comme une priorité stratégique de l’État.
Et techniquement, comment publier ses données ?
Les données, pour être accessibles par le plus grand nombre, sont publiées sur des plateformes opendata qui les agrègent. Un jeu de données est publié sous forme de fichier téléchargeable qui peut soit être chargé directement sur la plateforme, soit être publié sous forme de lien vers un serveur distant. Dans tous les cas, le fichier doit être mis à jour de manière régulière afin que le public ait accès à une information récente et pertinente, d’où la nécessité d’alléger cette tâche en l’automatisant.
Nous verrons dans cet article comment générer un fichier « dynamique » qui est régénéré automatiquement de manière régulière.
Note : Le fichier en question étant hébergé sur un serveur Linux, le protocole expliqué dans cet article est réalisé sous ce système d’exploitation.
L’Opendata, qu’est-ce que c’est ?

L’Opendata ou donnée ouverte est une donnée numérique dont l'accès et l'usage sont laissés libres aux usagers. Elle est diffusée de manière structurée selon une méthode et une licence ouverte garantissant son libre accès et sa réutilisation par tous, sans restriction technique, juridique ou financière.
Une donnée publique est une donnée produite ou reçue dans le cadre d’une mission de service public
L’Opendata, quels objectifs ?
L’Opendata s'inscrit dans une tendance qui considère l'information publique comme un bien commun dont la diffusion est d'intérêt public et général (Wikipedia). La publication en Opendata vise à :
- Renforcer la transparence de l’action publique
- Faciliter le travail des services publics
- Améliorer la connaissance et la recherche en valorisant la diffusion et la réutilisation des données
- Permettre la création de nouveaux services numériques et de nouveaux usages des données recueillies par les établissements publics en générant de l'activité économique autour de ces données

Après avoir pris connaissance des obligations et des opportunités liées à la diffusion des données publiques en Opendata, l’étape suivante consiste à créer le jeu de donnée qui sera publié.
1) Créer une vue dans la BDD
Les parcs nationaux disposent de bases des données pour stocker les informations de biodiversité et d’itinéraires de randonnées sur leur territoire (respectivement GeoNature et Geotrek). L’objectif est de mettre en forme les informations à publier dans une vue de la base de données. Une fois la vue créée, il faut en exporter le contenu dans un format de données qui facilitera sa réutilisation (ex : CSV, JSON…).
Exemple de vue pour extraire les randonnées et leurs patrimoines depuis une base de données Geotrek : Geotrek / export_rando_opendata.sql
2) Générer un fichier GeoJSON avec ogr2ogr
Il y a plusieurs moyens de récupérer la vue créée et de l’enregistrer au format souhaité. Il est possible notamment de passer par un logiciel SIG (ex : QGIS) en se connectant à la base de données PostGIS et en ouvrant le contenu de la vue afin de l’enregistrer sous forme de fichier dans un format choisi (Geopackage, GeoJSON...). Cependant cette méthode n’est pas la plus efficace en terme de temps. Il existe une méthode plus rapide, qui nécessite de passer en ligne de commandes avec la librairie GDAL/OGR. Une fois celle-ci installée, il est possible de manipuler des données géospatiales raster (GDAL) et vecteur (OGR). Une des commandes d’OGR, « ogr2ogr », permet de convertir des données vecteurs vers divers formats de fichiers, tout en réalisant d’autres opérations pendant le processus comme des sélections spatiales ou attributaires ou encore la définition du système de coordonnées en sortie. Vous pouvez retrouver la documentation de cette commande ici.
Pour installer GDAL/OGR :
sudo add-apt-repository ppa:ubuntugis/ppa && sudo apt-get update sudo apt-get install gdal-bin
Pour récupérer une vue créée dans une base de données avec ogr2ogr, il est nécessaire de renseigner les informations nécessaires pour se connecter à la base de données ainsi que la requête SQL qui permet de sélectionner les données souhaitées. Il faudra également renseigner le chemin de sortie du fichier, qui se trouve sur un site web connecté à un serveur distant. De cette manière, on dispose d’une URL qui sera notre lien de téléchargement pour le jeu de données publié sur la plateforme opendata.
Exemple de conversion de fichier en GeoJSON :
ogr2ogr -f "GeoJSON" home/pne/files/randos_pne.geojson PG:"host=**** user=**** dbname=****** password=*****" -sql "select * from public.v_opendata_treks"
Le format privilégié par le PNE pour publier des données spatiales est le GeoJSON car c’est un format ouvert et simple d’échange de données géographiques. Le PNE a fait le choix de publier également ses données en format CSV, format tabulaire, plus facilement réutilisable par des utilisateurs qui ne disposent pas d’outils cartographiques pour traiter les données en GeoJSON.
Exemple de conversion de fichier en CSV (itinéraires de randonnées) :
ogr2ogr -t_srs EPSG:4326 -f CSV -lco GEOMETRY=AS_WKT -lco SEPARATOR=SEMICOLON /home/pne/Data/files/randos_pne.csv PG:"host=**** user=**** dbname=****** password=*****" -sql "select * from public.v_opendata_treks"
Exemple de conversion de fichier en CSV (patrimoines associés) :
ogr2ogr -t_srs EPSG:4326 -f CSV -lco GEOMETRY=AS_XY -lco SEPARATOR=SEMICOLON /home/pne/Data/files/patrimoines_randos_pne.csv PG:"host=**** user=**** dbname=****** password=*****" -sql "select * from public.v_opendata_pois"
3) Mettre en place une tâche planifiée (Cron)
Nous allons mettre en place une tache planifiée sur un serveur pour automatiser la génération du fichier à intervalle régulier et le rendre accessible sur une URL fixe.
Sous le système d’exploitation Linux, c’est l’outil Crontab qui permet de lancer des tâches de façon automatisée et régulière. Vous trouverez toutes les informations pour mettre en place un Cron, c’est-à-dire une tâche planifiée automatisée, en suivant ce lien.
Il n’y a plus qu’à définir la temporalité à laquelle on souhaite régénérer le fichier et insérer la commande ogr2ogr.
Dans l’exemple suivant, nous créons une tache Cron pour l’utilisateur "root" qui s’exécutera sur le serveur tous les jours à 3 heures du matin. Pour le créer on exécute la commande "sudo crontab -e" puis on y inclut la commande :
0 3 * * * ogr2ogr -f "GeoJSON" /home/pne/files/randos_pne.geojson PG:"host=**** user=**** dbname=**** password=****" -sql "select * from public.v_opendata_treks"
Le chemin de sortie du fichier que nous avons renseigné se trouve sur un serveur distant. De cette manière, on dispose d’une URL qui sera notre lien de téléchargement du fichier pour le jeu de données publié sur la plateforme opendata.
4) Rendre le fichier téléchargeable
Pour que ce fichier soit accessible sur une URL en http, il faut ensuite créer une configuration Apache.
Exemple de configuration pour le domaine http://data.ecrins-parcnational.fr :
Dans le fichier "/etc/apache2/sites-available/data.conf" :
<VirtualHost *:80>
ServerName data.ecrins-parcnational.fr
DocumentRoot /home/user/Data/
<Directory /home/user/Data/>
Order deny,allow
Options +Indexes
Require all granted
</Directory>
# Forcer le telechargement des fichiers GEOJSON
<FilesMatch "\.(json|geojson)$">
ForceType application/octet-stream
Header set Content-Disposition attachment
</FilesMatch>
</VirtualHost>
Notre fichier des randonnées, mis à jour quotidiennement est ainsi accessible à l’URL permanente http://data.ecrins-parcnational.fr/files/randos_pne.geojson.
5) Publier votre jeu de données
Il ne reste maintenant plus qu’à plus publier le jeu de données en opendata. Il existe de nombreuses plateformes opendata où il est possible de déposer un jeu des données, vous pourrez voir un inventaire des plateformes de données territoriales (non exhaustif) ici. La plateforme qui a le plus de visibilité et qui recense le plus de données au niveau national est : data.gouv.fr, c’est pourquoi le PNE a fait le choix de publier ses jeux de données sur cette plateforme. Vous pourrez trouver la documentation pour publier sur data.gouv.fr ici.
On commence par créer et décrire le jeu de données, puis à y ajouter une ressource, sous forme d’URL vers notre fichier régénéré chaque jour, plutôt qu’en chargeant un fichier statique.
Capture de l’étape de publication d’un lien vers un fichier distant sur data.gouv.fr :
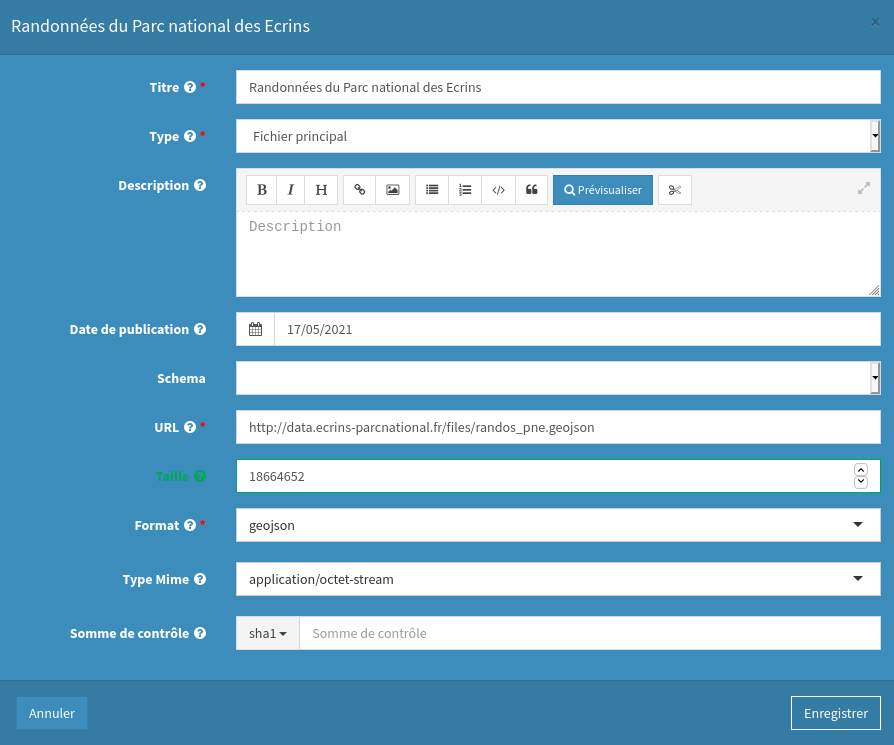
Exemples de publication de jeux de données du PNE :
- data.gouv.fr / Randonnées du Parc national des Ecrins
- data.gouv.fr / Patrimoines des randonnées du Parc national des Ecrins
- data.gouv.fr / Observations de biodiversité (faune-flore) du Parc national des Écrins
- Aussi disponibles sur DATA SUD
Pour en savoir plus sur l’opendata au Parc national des Ecrins :