Connecter des outils de dataviz à GeoNature
Elsa Guilley - Parc national des Ecrins / Avril 2019
1. Introduction
Dans le cadre du développement de l’application naturaliste GeoNature, ElasticSearch et Kibana sont apparus comme des logiciels intéressants et puissants pour la consultation des données de synthèse sous forme de graphiques, statistiques et cartes. Leurs outils de Machine Learning pourraient également se révéler être une solution efficace pour mettre en lumière les données déposées qui paraissent erronées.
L’application Metabase, bien que moins puissante, s’est avérée être une solution simple d’utilisation pour créer rapidement des diagrammes divers et variés avec ces mêmes données de synthèse.
2. ElasticSearch et Kibana
ElasticSearch est un moteur de recherche utilisant Lucene, permettant l'indexation et la recherche de données personnalisées. Concrètement, il s’agit d’une base de données NoSQL pouvant stocker de gros volumes de documents (sous format json), que l’on peut interroger de manière précise grâce à un langage de requêtes HTTP offrant de nombreuses fonctionnalités. Ainsi, cet outil présente sa propre API d’accès aux données (très rapide) et s’utilise donc avec n’importe quel langage de programmation.
Ce logiciel, écrit en Java et distribué sous licence Apache, est gratuit, libre et open source.
Lucene est une bibliothèque open source qui offre la possibilité d’indexer et de chercher des données, essentiellement de type texte. Il s’agit d’une couche intermédiaire entre les données et les programmes. Les index attribués aux documents, de formats divers et variés, permettent de faciliter la recherche de contenu (rapide et efficace).
ElasticSearch s’inscrit dans la suite Elastic qui comprend également le module Kibana. Cette interface permet de visualiser les données ElasticSearch sous forme de représentations graphiques créées par l’utilisateur lui-même : histogrammes, graphes linéaires, camemberts… tout ça sans une ligne de code. Il est également possible de visualiser des données géographiques sur une carte. Les diagrammes réalisés peuvent être regroupés au sein de tableaux de bord personnalisés, destinés à être partagés.
Kibana présente également une fonctionnalité de Machine Learning permettant de modéliser en temps réel le comportement des données ElasticSearch (tendances, périodicité…), afin d’identifier les problèmes le plus rapidement possible, tels que des intrus ou des erreurs d’infrastructure.
Enfin, le module Logstash, qui a également été testé dans cette étude, est un logiciel capable d'importer des données en provenance d’un grand nombre de sources, de les uniformiser en les transformant et de les envoyer vers un système de stockage (ElasticSearch en l’occurrence).
a. Installation
L’installation suivante a été réalisée sous Linux (Ubuntu 18.04.2 LTS).
Avant d’installer ElasticSearch, il est important d’installer Java :
Installez Java :
sudo apt-get install default-jre
Installez OpenJDK 8 (Java Development Kit) :
sudo apt-get install default-jdk
Quelques étapes supplémentaires afin d’installer le JDK :
Ajoutez le PPA (Personal Package Archives) d’Oracle :
sudo add-apt-repository ppa:webupd8team/java
Mettez à jour le répertoire de fichiers disponibles :
sudo apt-get update
Installez Oracle JDK 8 :
sudo apt-get install oracle-java8-installer
Il est maintenant possible d’installer et de configurer ElasticSearch :
Importez la clé publique GPG d’ElasticSearch dans apt :
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Ajoutez Elastic au répertoire de fichiers disponibles :
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Mettez à jour le répertoire de fichiers disponibles :
sudo apt-get update
Installez ElasticSearch :
sudo apt install elasticsearch
Il est nécessaire de configurer l’adresse du serveur ElasticSearch :
Modifiez le fichier principal de configuration :
sudo nano /etc/elasticsearch/elasticsearch.yml
. . . network.host: localhost . . .
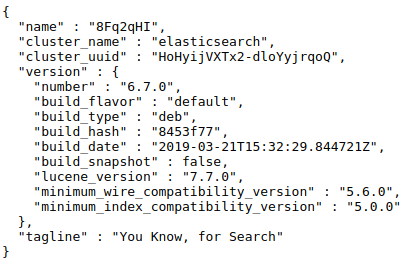
Pour vous assurer du bon fonctionnement d’ElasticSearch, vous pouvez saisir localhost:9200 (ElasticSearch est branché sur le port 9200) dans votre navigateur. ElasticSearch doit retourner (à peu près) les lignes suivantes :
Afin d’importer des données au sein d’ElasticSearch, nous allons installer le module Logstash :
Installez Logstash :
sudo apt install logstash
Configurez :
cd /usr/share/logstash/bin
sudo ./logstash-plugin install logstash-input-jdbc
Enfin, nous pouvons installer Kibana :
Installez Kibana :
sudo apt install kibana
Autorisez et lancez le service :
sudo systemctl enable kibana
sudo systemctl start kibana
b. Importer des données au sein d’ElasticSearch
Commençons par importer des données provenant de la BDD GeoNature (PostGreSQL) au sein d’ElasticSearch avec Logstash. Pour cela, placez vous dans le répertoire bin de logstash :
cd /usr/share/logstash/bin
Il est nécessaire de créer et d’éditer un fichier de configuration :
sudo nano test.conf
Nous allons importer les données correspondant à la table "synthese" (input). Le résultat de la requête SQL est ensuite intégré à ElasticSearch (output). Complétez le fichier avec les lignes suivantes et les informations qui vous sont propres :
input{
jdbc{
jdbc_connection_string => "jdbc:postgresql://localhost:5432/geonature2db?user=<nom_utilisateur>&password=<mdp>&ssl=true"
jdbc_user => "<nom_utilisateur>"
jdbc_validate_connection => true
jdbc_driver_library => "/<chemin>/postgresql-9.4-1203.jdbc42.jar"
jdbc_driver_class => "org.postgresql.Driver"
statement => "SELECT * FROM gn_synthese.synthese"
jdbc_paging_enabled => true
jdbc_page_size => 10000
}
}
output{
elasticsearch{
"index" => "syntheses"
"document_type" => "synthese"
"document_id" => "%{id_synthese}"
"hosts" => "localhost:9200"
}
}
Quelques précisions :
- Vous devez télécharger la version 9.4 Build 1203 JDBC 4.2 du fichier jar du pilote JDBC (présente sur la page suivante : https://jdbc.postgresql.org/download.html), puis indiquer le chemin menant à ce fichier dans l'option "jdbc_driver_library".
- La requête SQL doit être écrite selon les normes de PostGreSQL.
- C’est à vous de choisir les noms d’index et de type de document. Par exemple, si l’on souhaite obtenir toutes les lignes de la table "taxref" pour lesquelles le règne est "Animalia", il est possible de définir : index = "taxonomie" et "document_type" = "animalia".
/!\ Pas de majuscule pour ces deux champs - L’identifiant mentionné pour "document_id" doit correspondre à un identifiant unique concernant la requête demandée ! S’il n’y en a pas (cas d’une requête complexe), il est nécessaire de créer une vue matérialisée en y ajoutant un identifiant unique.
- Les options "jdbc_paging_enabled" et "jdbc_page_size" ne sont pas obligatoires dans tous les cas. Elles sont seulement nécessaires pour traiter des requêtes engageant de très gros volumes de données (de l’ordre du million).
Après avoir enregistré le fichier, exécutez la commande logstash pour importer les données :
sudo ./logstash -f test.conf –path.settings=/etc/logstash
Pour visualiser le résultat de la requête dans ElasticSearch, saisissez l’URL suivante dans votre navigateur :
localhost:9200/syntheses/synthese/_search?pretty
ElasticSearch renvoie alors les données indexées sous format json.
c. Se familiariser avec Kibana
Nous allons à présent visualiser ces données avec Kibana. Tout d’abord, lancez l’interface (si cela est nécessaire) :
cd /usr/share/kibana
sudo ./bin/kibana
Pour accéder à Kibana, saisissez localhost:5601 (Kibana est branché sur le port 5601) dans votre navigateur. Vous êtes redirigé vers la page suivante :
Avant de pouvoir manipuler les données, il est nécessaire de les récupérer depuis ElasticSearch grâce à la création d’un nouvel index. Un index correspond en fait à l’aspect relationnel d’une base de données ; il permet d’organiser les documents (autrement dit les entrées d’une table en termes de base de données) de manière à accélérer les requêtes de recherche.
Pour ce faire, placez vous dans l’onglet « Management », puis cliquez sur « Index Patterns ». Cliquez sur le bouton « Create index pattern », puis entrez le nom de l’index que vous avez implémenté précédemment. Si les données ont été importées correctement, le nom de l’index devrait être reconnu et vous pouvez passer à l’étape suivante.
Si vos données contiennent un champ date, vous pouvez le sélectionner en
tant que filtre temporel (ici nous choisissons « date_min »). Si ce n’est
pas le cas, sélectionnez l’option « I don’t want to use the Time Filter ».
Pour finir, cliquez sur le bouton « Create index pattern ».
Après cela, vous avez accès aux champs compris dans l’index créé ainsi
qu’à différentes précisions à leur sujet :
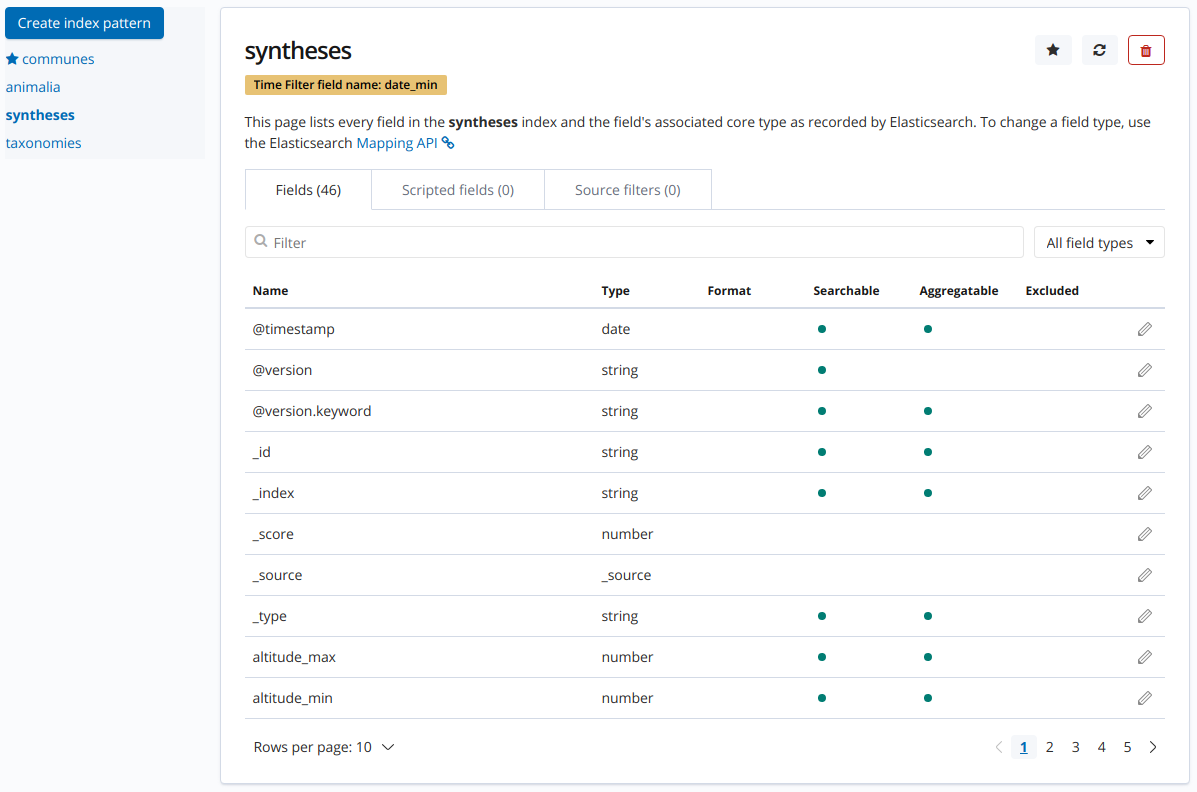
Libre à vous de modifier certaines caractéristiques de ces champs.
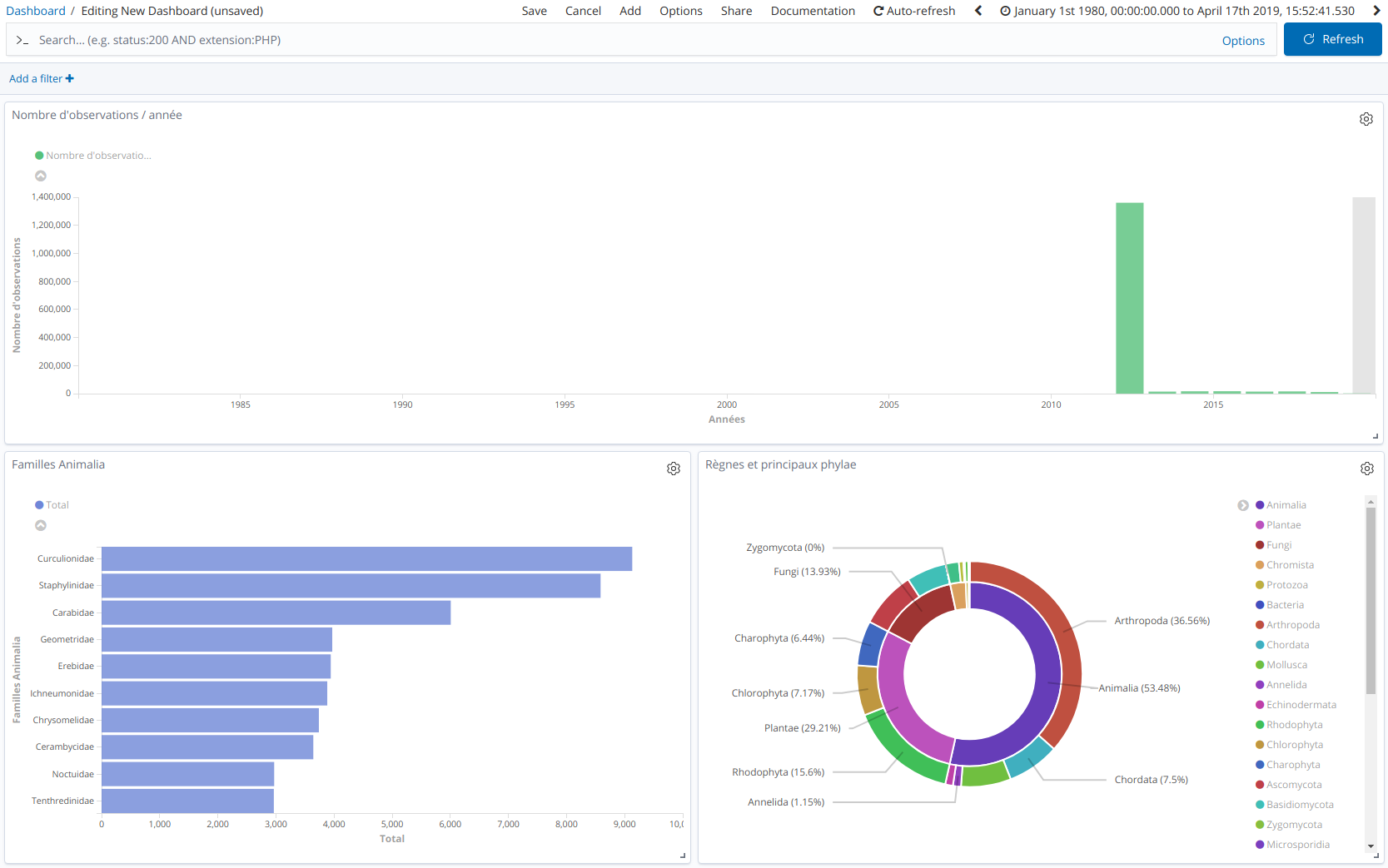
Maintenant que les données ont été récupérées sur Kibana, placez vous dans l’onglet « Visualize ». En cliquant sur « + », vous pouvez créer un nouveau diagramme. Nous allons voir ici comment réaliser un histogramme du nombre d’observations par année. Tout d’abord, sélectionnez « Vertical bar » puis l’index « syntheses ». Ensuite, les options à mentionner sont indiquées sur la capture ci-dessous.
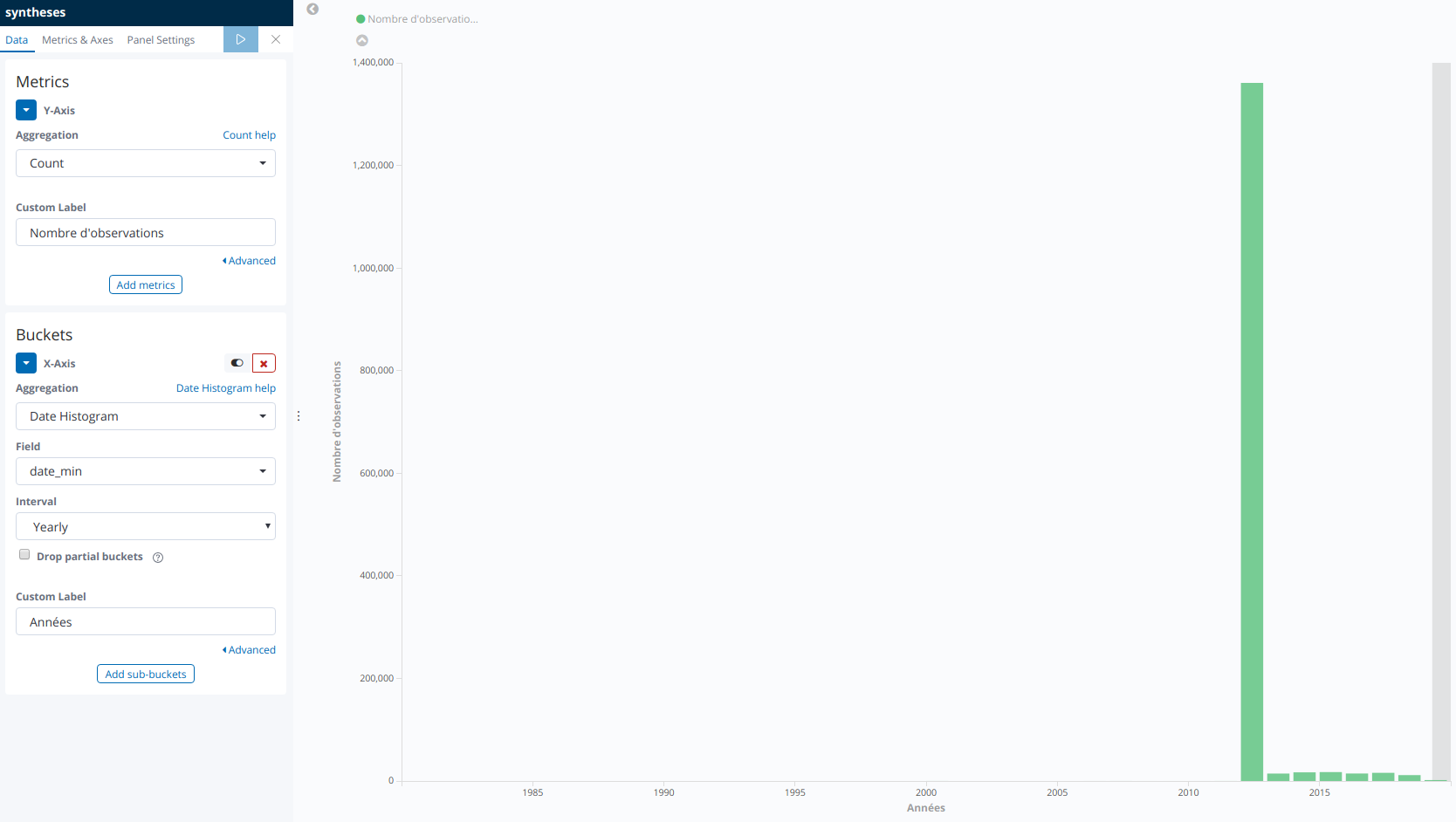
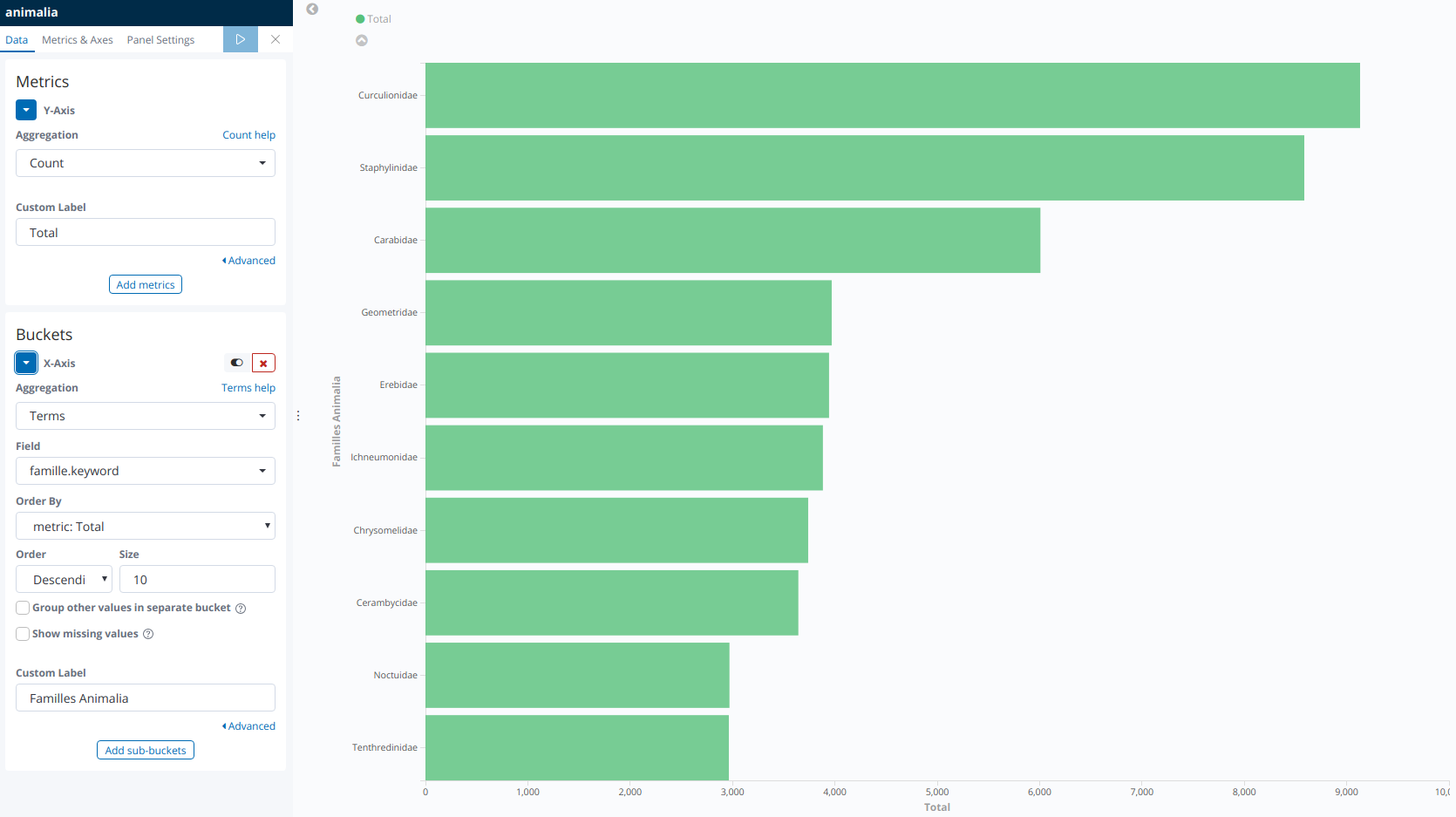
Voici un autre exemple sans filtre temporel, permettant de représenter le nombre de taxons au sein des principales familles du règne « Animalia ». Ce diagramme a été réalisé en créant un nouvel index dont les données proviennent de la table « taxref » de la BDD GeoNature (règne Animalia uniquement).
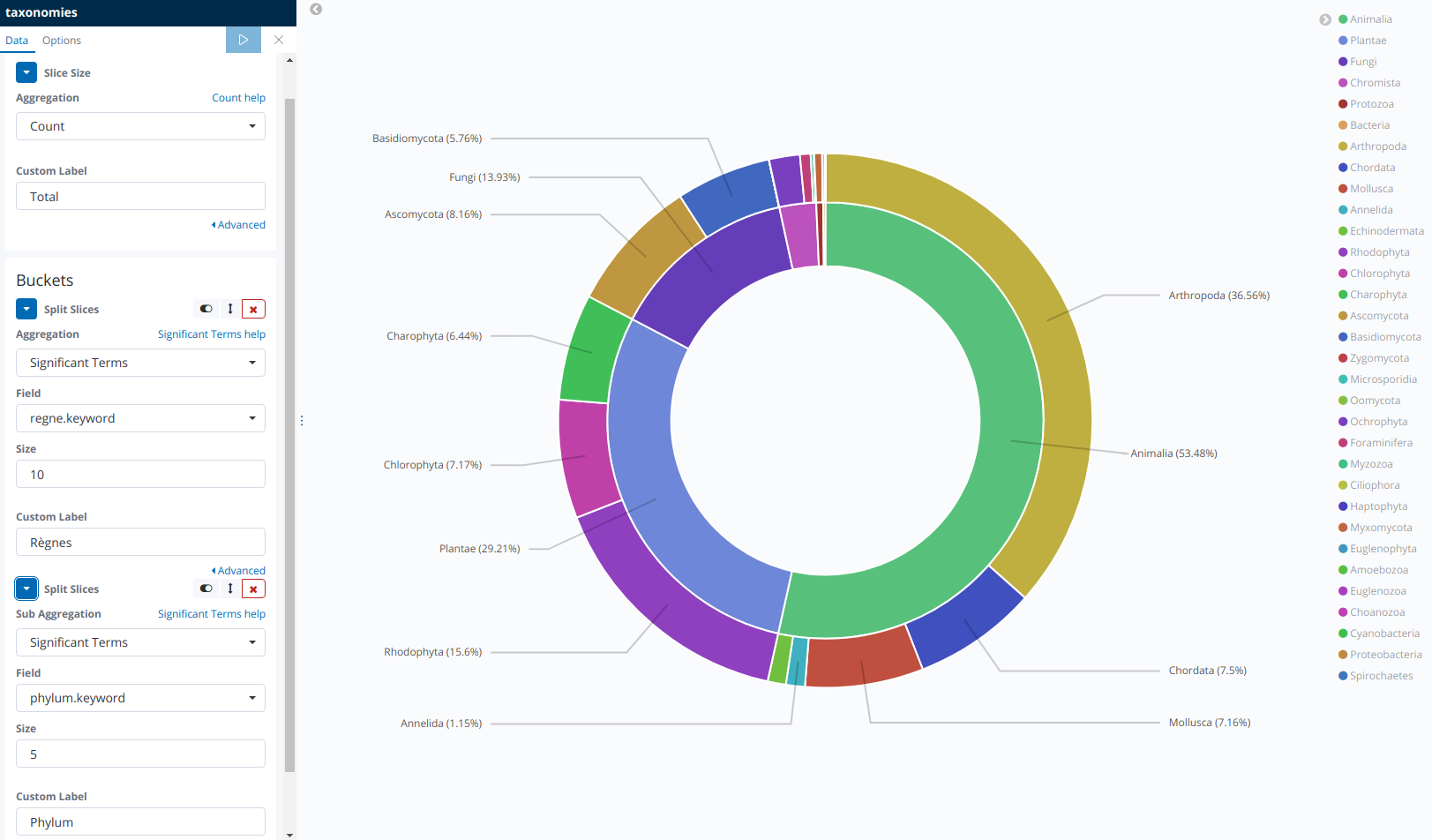
Enfin, un exemple de camembert permettant de connaître la part des différents règnes et principaux phylum au sein de la table « taxref ».
A vous de jouer pour explorer les autres fonctionnalités de visualisation de Kibana !
Pour enregistrer votre diagramme, il vous suffit de cliquer sur l’option « Save » en haut de la page. Vous pouvez le consulter (et le modifier) à tout moment en cliquant sur l’onglet « Visualize » : la liste des graphiques enregistrés y est exposée.
Nous pouvons terminer par la création d’un tableau de bord regroupant les 3 diagrammes créés. Pour cela, rendez-vous dans l’onglet « Dashboard », puis cliquez sur « New dashboard ». Dans l’option « Add » en haut de la page, vous pouvez sélectionner les diagrammes que vous souhaitez afficher ensemble, et les placer comme bon vous semble.
Pour sauvegarder votre tableau de bord, il vous suffit à nouveau de cliquer sur « Save » en haut de la page. Il est également possible de le partager en cliquant sur « Share ». Vous pouvez consulter (et modifier) vos tableaux de bord à tout moment en cliquant sur l’onglet « Dashboard ».
d. Utiliser les requêtes ElasticSearch pour d’autres programmes
Comme cela a été précisé précédemment, ElasticSearch possède son propre langage de requêtes, adaptable dans différents langages de programmation tels que Java, Python, PHP… Nous allons étudier ici quelques requêtes simples pour cerner les bases de ce langage qui peut s’avérer rapidement complexe.
Pour commencer, il est important de faire la différence entre les « query » et les « filter » :
- Les « query » permettent de répondre à la question « A quel point le résultat répond à la requête demandée ? ». En plus de vérifier si le résultat correspond à la requête, ElasticSearch renvoie un score rendant compte du degré de correspondance de ce résultat, par rapport aux autres qui ont également été retenus. Ainsi, des résultats qui ne correspondent pas exactement à la requête mais qui s’en rapprochent peuvent faire partie des réponses. On reconnaît ici le rôle de moteur de recherche d’ElasticSearch.
- Les « filter » répondent quant à eux à la question « Est-ce que le résultat répond à la requête ? ». Dans ce cas, il n’y a pas de score. La réponse est tout simplement « Oui » ou « Non ». Cette fonction s’apparente aux rôles des requêtes SQL interrogeant une BDD.
A vous d’utiliser l’une ou l’autre de ces fonctionnalités en fonction de vos besoins. Leurs utilisations respectives sont détaillées dans les paragraphes suivants.
Match query
Ce type de requête permet de chercher un ou plusieurs mots au sein d’un champ :
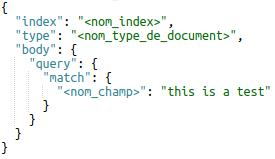
Il est possible de rajouter l’option « operator » pour préciser si TOUS les mots de la recherche doivent être présents dans les résultats (« and »), ou si la présence d’un seul d’entre eux suffit (« or »). Ce paramètre est défini sur « or » par défaut.
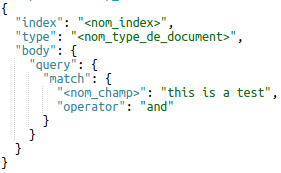
La requête « match_phrase » peut également être utilisée à la place de « match ». Elle fonctionne de la même manière en tenant compte de l’ordre des mots de l’expression renseignée.
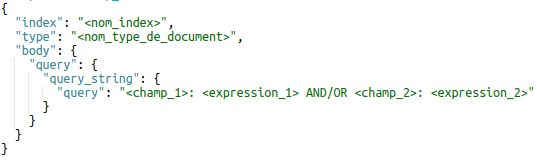
Query string query
Cette requête permet dans un premier temps de rechercher une même expression dans différents champs :

Elle permet également de rechercher différentes expressions dans des champs différents :
Filter
Le paramètre « term » correspond à la clause WHERE d’une requête SQL :

Le paramètre « range » agit de même en permettant de filtrer sur des champs numériques ou des dates :

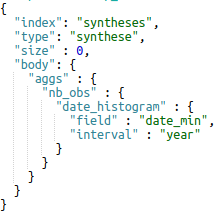
Enfin, le paramètre « aggs » permet de réaliser des GROUP BY. Son utilisation est assez complexe, c’est pourquoi seront présentés ici deux exemples.
Somme du nombre d’observations par commune :

Nombre d’observations par année :
e. Perspectives
L’intégration de données à référence spatiale et les possibilités de représentations cartographiques proposées par Kibana n’ont pas été explorées, mais pourraient permettre de créer, par exemple, des cartes du nombre d’observations par maille, par commune…
Concernant ElasticSearch, les capacités de recherche offertes pas le logiciel, notamment à travers les « query », pourraient approfondir et compléter le travail qui a déjà été réalisé pour améliorer la recherche de taxons au sein de la table "taxref" (https://si.ecrins-parcnational.com/blog/2019-01-fuzzy-search-taxons.html).
Enfin, ElasticSearch n’est pas le seul moteur de recherche open source et performant que l’on peut trouver sur le marché. SolR est également une solution basée sur Lucene offrant les mêmes fonctionnalités. Cependant, notre choix s’était porté sur ElasticSearch lors de cette étude en raison de sa meilleure documentation et de sa facilité de mise en place et d’utilisation. SolR est un logiciel plus adaptable aux différents besoins mais il nécessite davantage de temps pour le maîtriser.
3. Metabase
Metabase est un outil de reporting de données qui se différencie des autres solutions similaires notamment par sa simplicité d’installation et d’utilisation. Cette application open source repose sur un système de questions/réponses : l’utilisateur interroge ses données sous forme de « questions » (formatées par l’application grâce à des filtres), qui sont en réalité des requêtes SQL cachées, et obtient des « réponses » simples sous forme de tableaux tout d’abord, puis au moyen de graphiques en tout genre selon ses envies. Les données peuvent provenir de bases de données variées : MySQL, PostGreSQL, SQL Server, Oracle...
Cette solution est très pratique pour les utilisateurs qui ne possèdent pas les compétences pour coder en SQL. Toutefois, il est possible de produire des requêtes SQL pour accéder à des résultats plus avancés.
Comme pour Kibana, les diagrammes créés peuvent être exposés dans des tableaux de bord et partagés, grâce à des liens, dans d’autres programmes.a. Installation
L’installation suivante a été réalisée sous Linux (Ubuntu 18.04.2 LTS).
Avant d’installer Metabase, il est nécessaire de vérifier que Java est bien installé :
Vérifiez votre version de Java :
java -version
Si vous obtenez une erreur ou bien une réponse indiquant une version de Java plus ancienne que la version 1.8, vous devez installer le Java Runtime (JRE). Pour cela, reportez-vous aux premières étapes de la partie Installation d’ElasticSearch et Kibana.
Pour installer Metabase, il est nécessaire de télécharger le fichier jar qui sera exécuté en ligne de commande : Pour ce faire, rendez-vous sur la page suivante : https://metabase.com/start/jar.html.Puis cliquez sur le bouton « Download Metabase.jar ».
Il est maintenant possible d’installer Metabase :
Placez-vous dans le dossier où le fichier jar a été téléchargé :
cd <chemin_dossier>
Lancez Metabase :
java -jar metabase.jar
C’est aussi simple que cela !
Pour vérifier que le lancement a réussi et accéder à l’application, saisissez
localhost:3000 (Metabase est branché sur le port 3000) dans votre navigateur.
La page suivante s’affiche :
b. Jouer avec Metabase
La première étape à suivre est la configuration de Metabase. Nous allons, comme pour ElasticSearch, importer des données provenant de la BDD GeoNature. Pour cela, nous allons connecter cette BDD à Metabase.
Cliquez sur « Let’s get started ». Metabase vous demande alors de renseigner quelques informations vous concernant, comme votre Prénom et votre Nom, votre adresse e-mail… Complétez ce formulaire avec les informations qui vous sont propres, puis cliquez sur « Next ».
A ce stade, Metabase vous propose une connexion à une BDD. Pour cela, sélectionnez le type de BDD « PostGreSQL » puis remplissez les champs suivants (le nom d’utilisateur et le mot de passe vous sont propres) :
- Name : GeoNature
- Host : localhost
- Port : 5432
- Database name : geonature2db
- Database username : <nom_utilisateur>
- Database password : <mot_de_passe>
Puis cliquez sur « Next ».
Enfin, Metabase vous demande l’autorisation de collecter des informations de manière anonyme sur l’utilisation que vous faîtes de l’application. Après avoir fait votre choix, cliquez sur « Next ». Vous pouvez à présent, si vous le souhaitez, renseigner votre adresse e-mail pour vous abonner à la newsletter.
Cliquez ensuite sur « Take me to Metabase ». Vous arrivez sur une page ressemblant à peu près à cela :
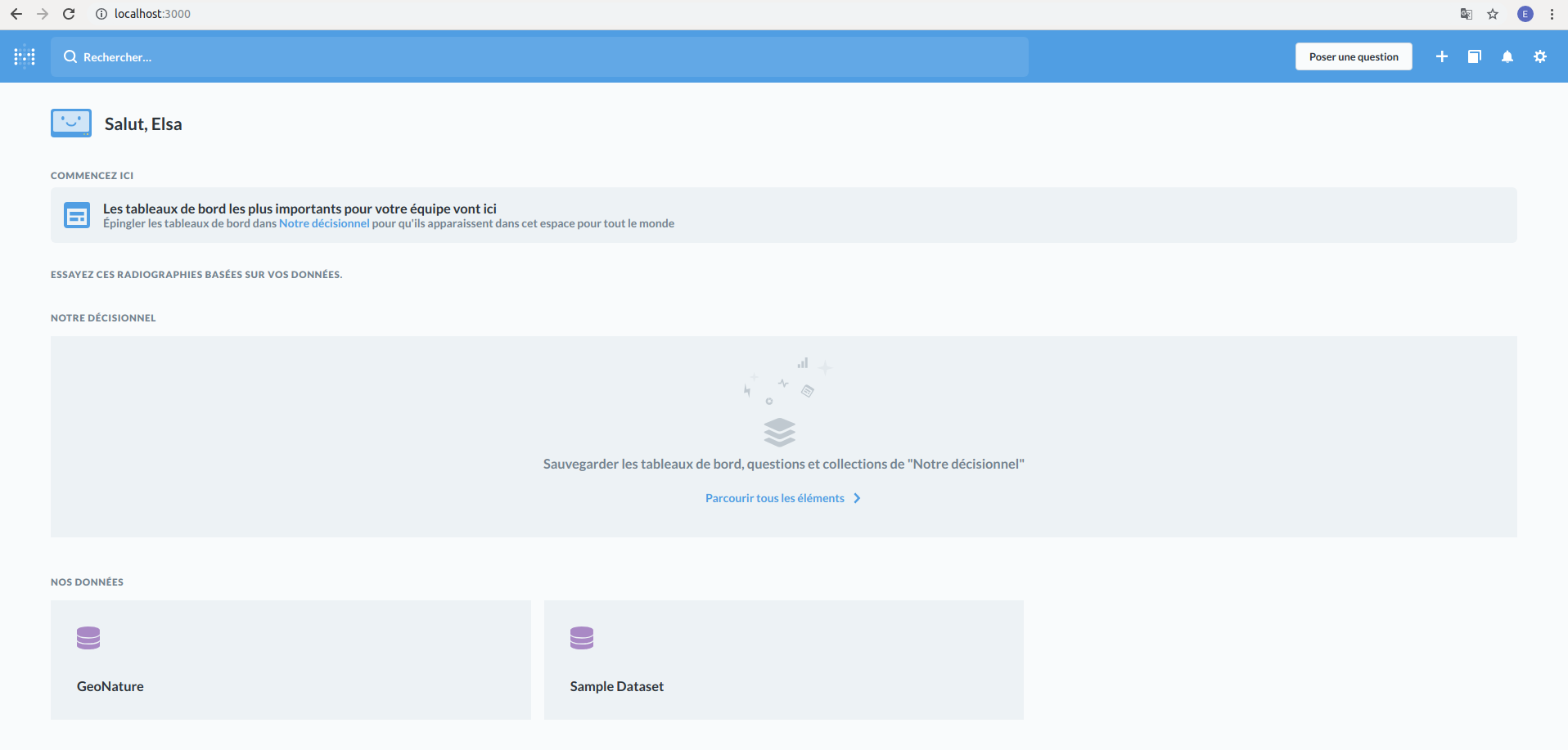
Si la BDD GeoNature n’apparaît pas dans la section « Nos données » (ça peut arriver...), il vous faudra la reprogrammer. Pour ce faire, cliquez sur l’icône « Paramètres » en haut à droite de l’écran, puis sur « Administration ». Rendez-vous dans « Ajouter une base de données », puis complétez les informations comme vous l’avez réalisé précédemment.
Maintenant que la BDD GeoNature est connectée à Metabase, nous allons apprendre à poser une « question » à l’application afin de connaître le nombre d’observations par année.
Pour cela, cliquez sur la BDD GeoNature dans la section « Nos données ». Vous arrivez sur cette page listant les schémas de la BDD :
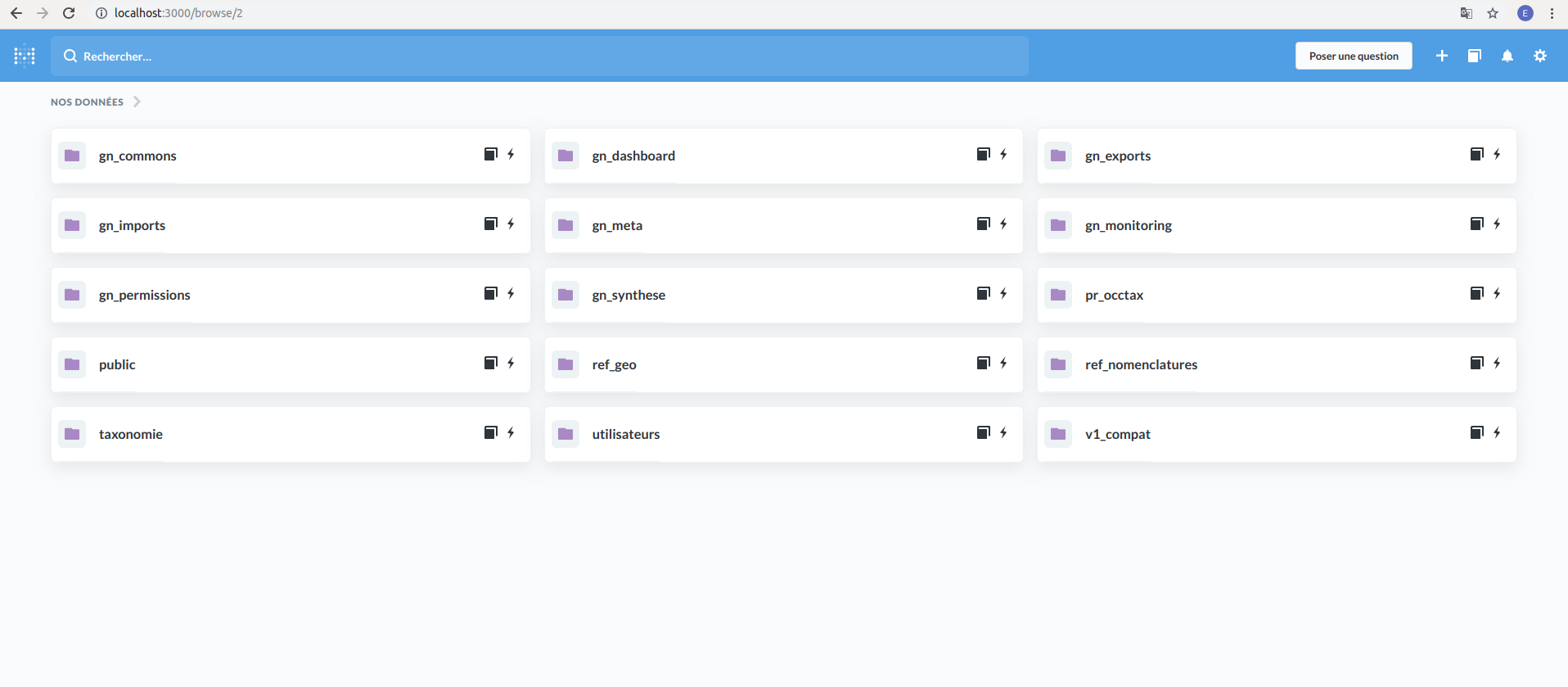
Sélectionnez le schéma « gn_synthese », puis la table « Synthese ». La page suivante apparaît, listant les données de la table :
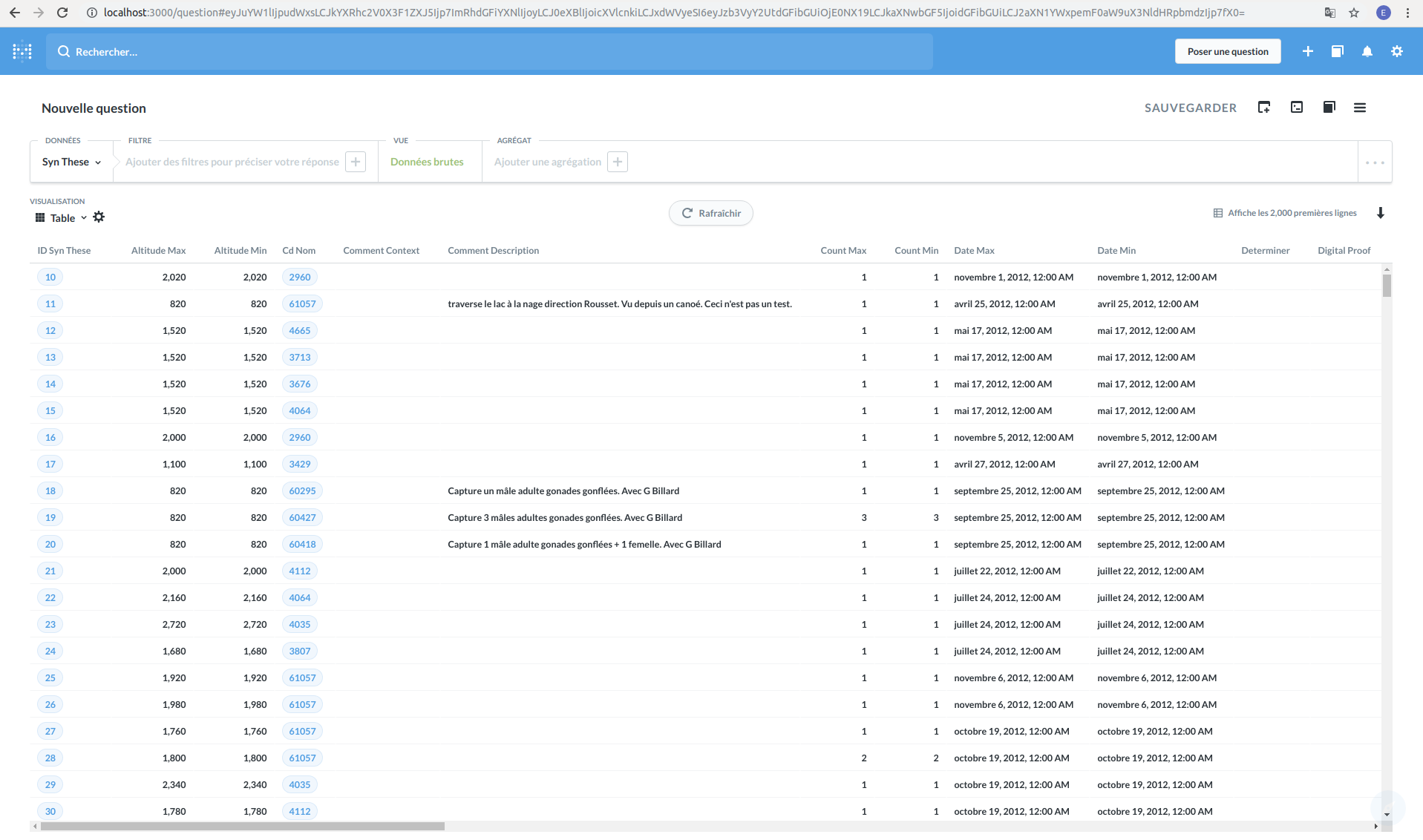
Dans la barre de requête située sous « Nouvelle question », sélectionnez « Nombre de lignes » pour « Vue » et « Date_min : Année » pour « Agrégat » (il faut cliquer à l’extrémité droite de la case « Date_min » pour choisir « par année »). « Agrégat » correspond en fait à un GROUP BY en requête SQL, et « Filtre » à une clause WHERE. « Vue » permet de déterminer ce qu’il y a dans le SELECT. Il est également possible de trier les résultats selon un critère en cliquant sur le bouton « ... » à l’extrémité droite de la barre, puis sur « Choisir un champ selon lequel trier ».
Validez votre question en cliquant sur « Obtenir la réponse ». Metabase vous renvoie le tableau suivant :
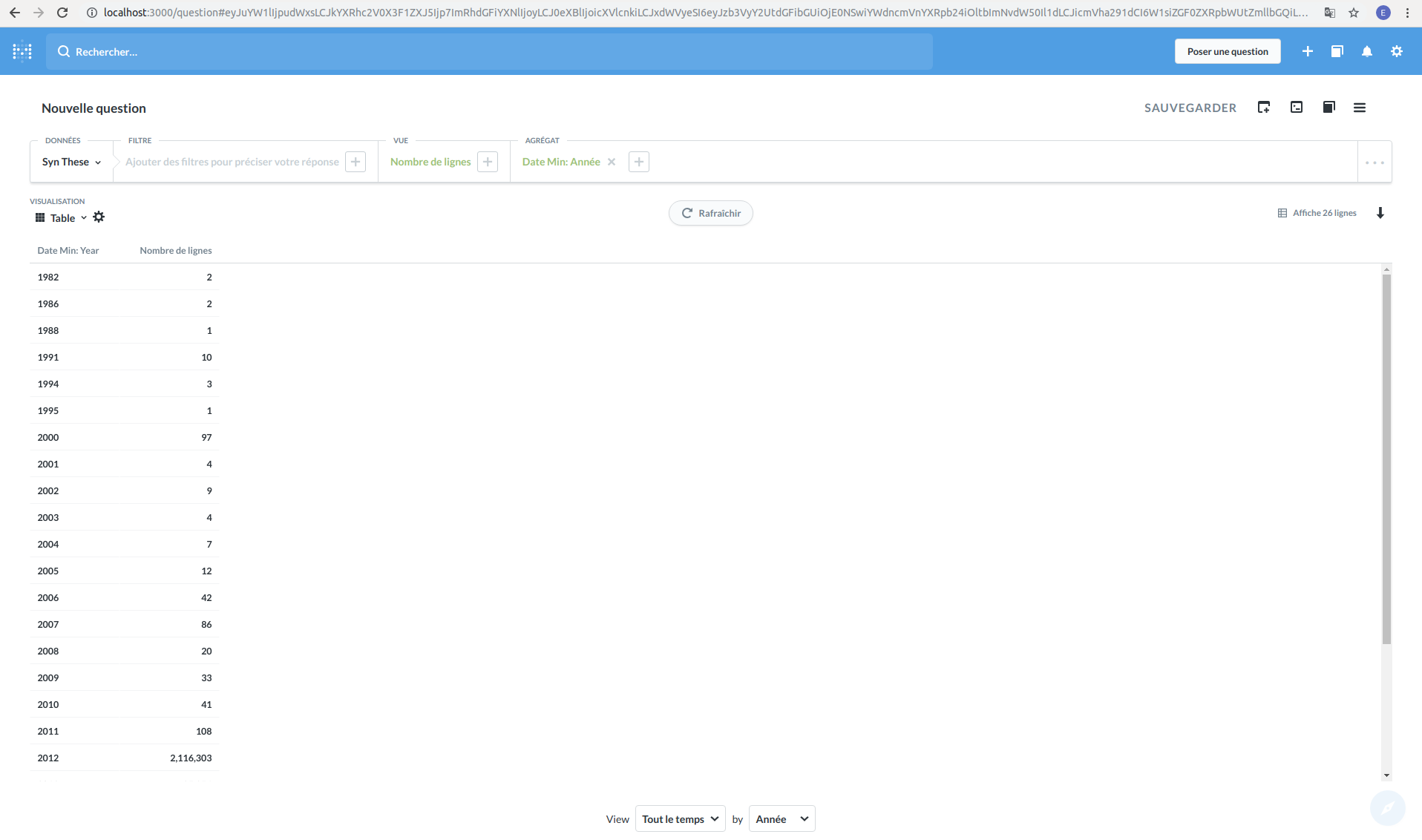
Afin de visualiser ce résultat sous forme d’histogramme comme pour Kibana, sélectionnez l’option « Histogramme » dans la liste déroulante de la fonctionnalité « Visualisation » (et non « Table » comme c’est défini actuellement) :
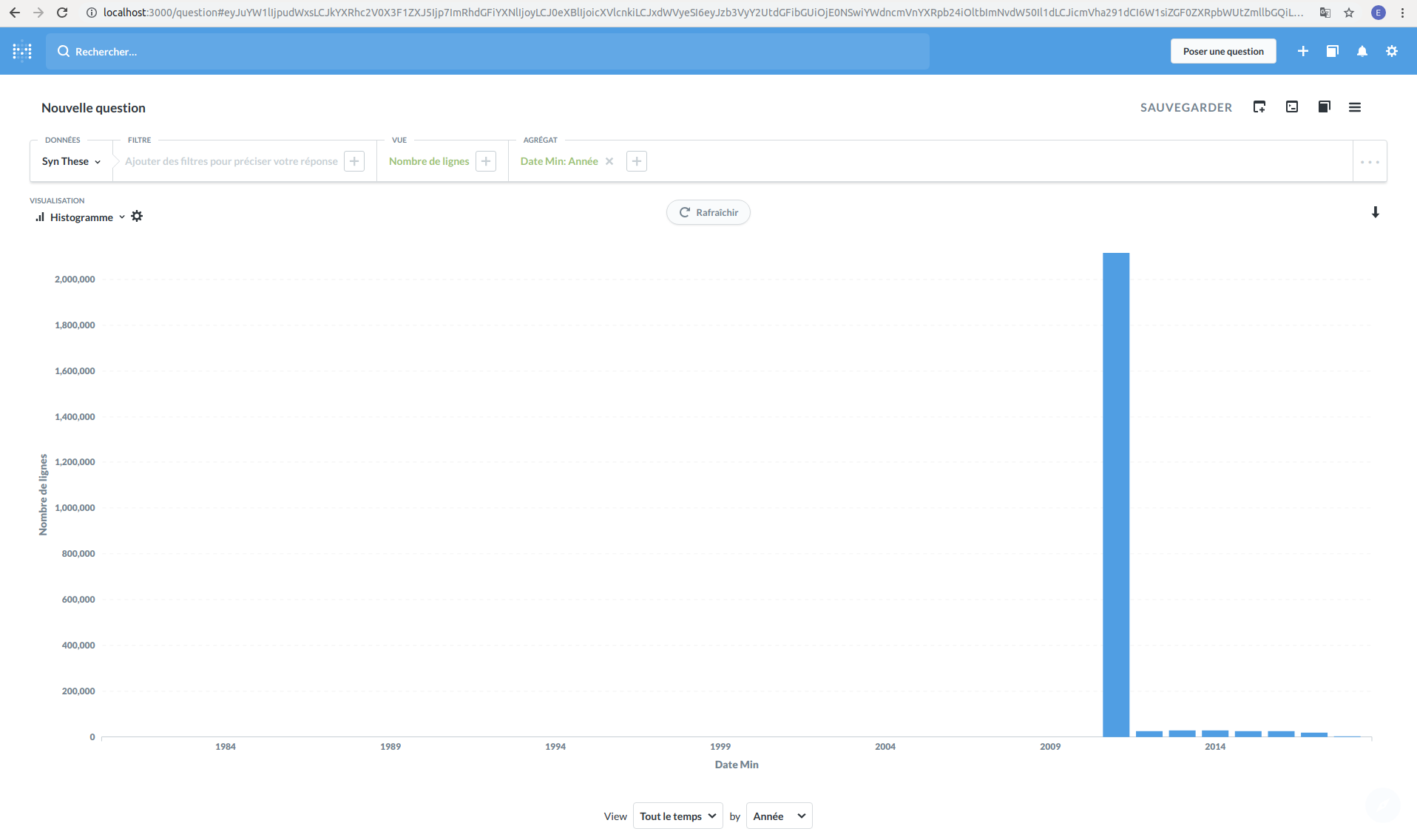
Vous pouvez personnaliser le graphique (libellés, couleurs…) en cliquant sur l’icône de paramètres à droite du type de visualisation.
Pour obtenir le code SQL de votre requête, il vous suffit de cliquer sur l’icône « Voir le SQL » en haut à droite (au-dessus de la barre de question).
Pour sauvegarder votre histogramme, cliquez sur « SAUVEGARDER » en haut à droite. Donnez-lui un nom et une description si besoin, puis sélectionnez la collection dans laquelle vous allez l’enregistrer. De retour dans le menu principal, vous pouvez retrouver (et modifier) vos diagrammes sauvegardés en cliquant sur « Parcourir tous les éléments » au centre de l’écran, puis en choisissant la collection qui vous intéresse.
Pour générer un diagramme en produisant une requête SQL (une vraie, sans question !), il vous faudra cliquer sur le bouton « Poser une question » en haut à droite de l’écran (bande bleue), puis sélectionner la case « Requête native ».
Pour créer un tableau de bord, il vous suffit de cliquer sur le « + » en haut à droite de l’écran (bande bleue) et de sélectionner « Nouveau tableau de bord ». Metabase vous demande de renseigner un nom de tableau ainsi qu’une description facultative, puis de déterminer la collection dans laquelle celui-ci sera rangé. Vous êtes dirigé vers cette page :
En cliquant sur le « + » en haut à droite (bande blanche cette fois-ci), vous pouvez ajouter au tableau de bord des diagrammes que vous avez enregistrés. Lorsque vous en avez sélectionné un, il est possible de personnaliser, entre autres, sa taille ainsi que son emplacement. Le tableau de bord est maintenant en mode édition.
Vous pouvez également ajouter des filtres en cliquant sur l’icône « Ajouter un filtre » à côté du « + » (bande blanche). Si vous souhaitez, par exemple, pouvoir filtrer l’histogramme que nous avons créé en fonction du règne des espèces observées, il vous faut sélectionner « Autres catégories ». L’écran suivant est alors celui que vous obtenez :
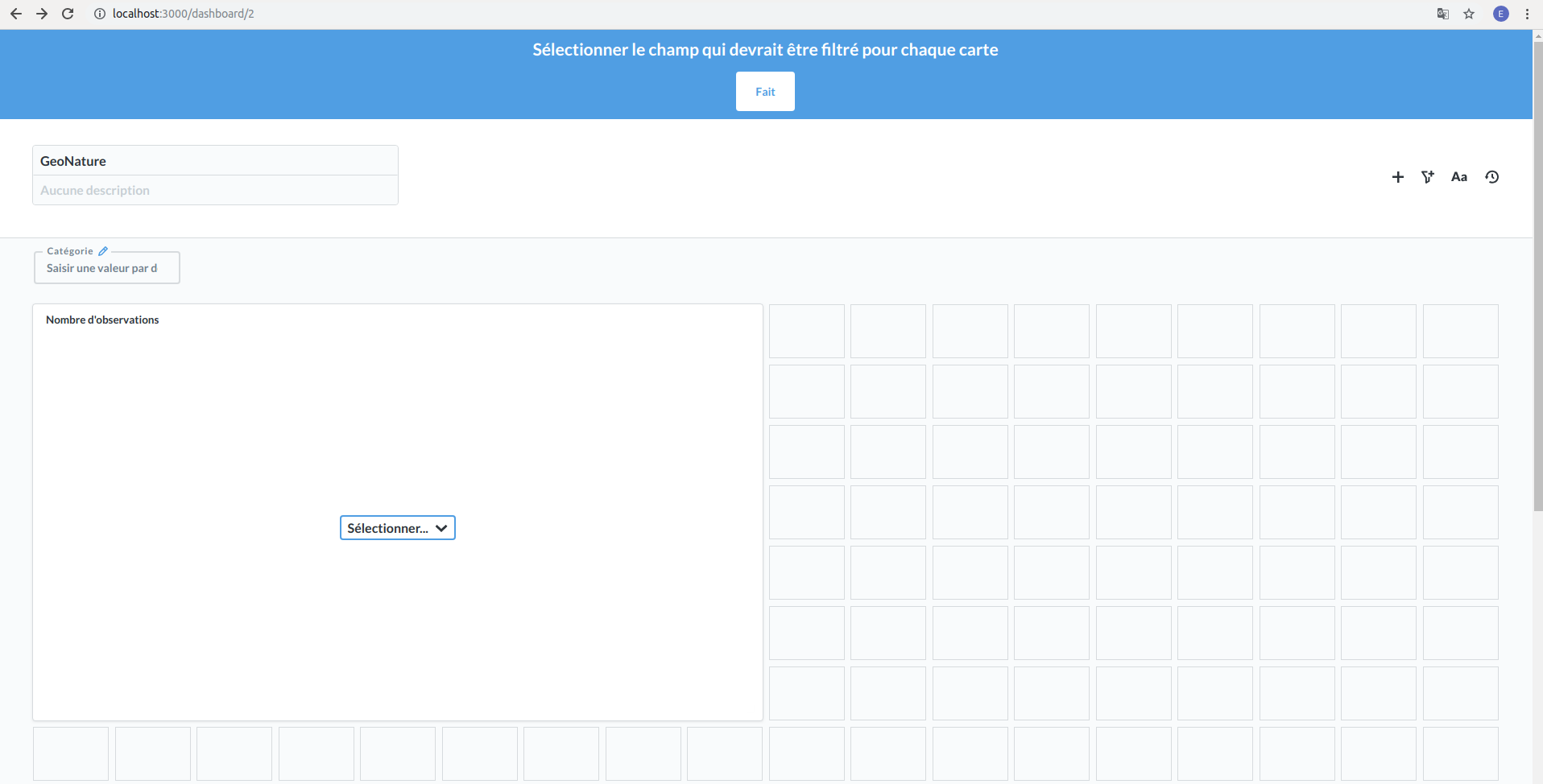
Vous devez ensuite, sur le diagramme, sélectionner le champ « Regne ». Vous pouvez également changer le titre du filtre en cliquant sur le petit crayon bleu à droite de « Catégorie » et saisir une valeur par défaut (facultatif). Une fois tout cela effectué, vous pouvez cliquer sur le bouton « Fait » dans la bannière bleue en haut de l’écran.
Il est possible d’insérer une zone de texte au tableau de bord en cliquant sur l’icône « Ajouter une zone de texte », toujours en haut à droite (bande blanche).
Pour sortir du mode édition et sauvegarder votre tableau de bord, il vous suffit de cliquer sur « Sauvegarder » en haut à droite (bande bleue). Vous pouvez maintenant utiliser le(s) filtre(s) que vous avez créé(s). Pour retourner en mode édition sans insérer de nouveau graphique, il vous suffit de cliquer sur l’icône crayon « Modifier le tableau de bord » (bande blanche). De retour dans le menu principal, vous pouvez retrouver (et modifier) vos tableaux de bord sauvegardés de la même manière que pour les graphiques.
4. Sources
- How To Install Java with Apt-Get on Ubuntu
- How To Install Elasticsearch, Logstash, and Kibana (Elastic Stack) on Ubuntu 18.04
- ElsticSearch documentation
- ElasticSearch ou SolR pour votre moteur de recherche ?
- Metabase documentation
- Metabase ou comment faire parler vos datas